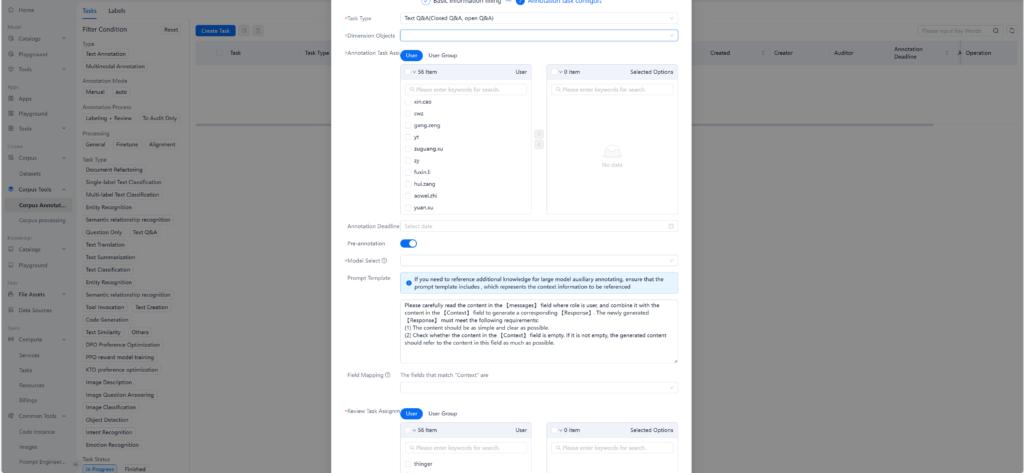
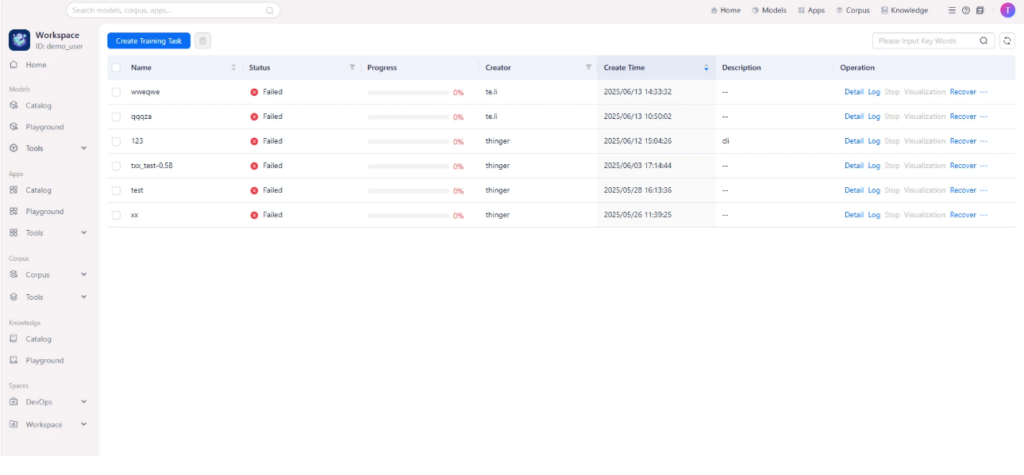
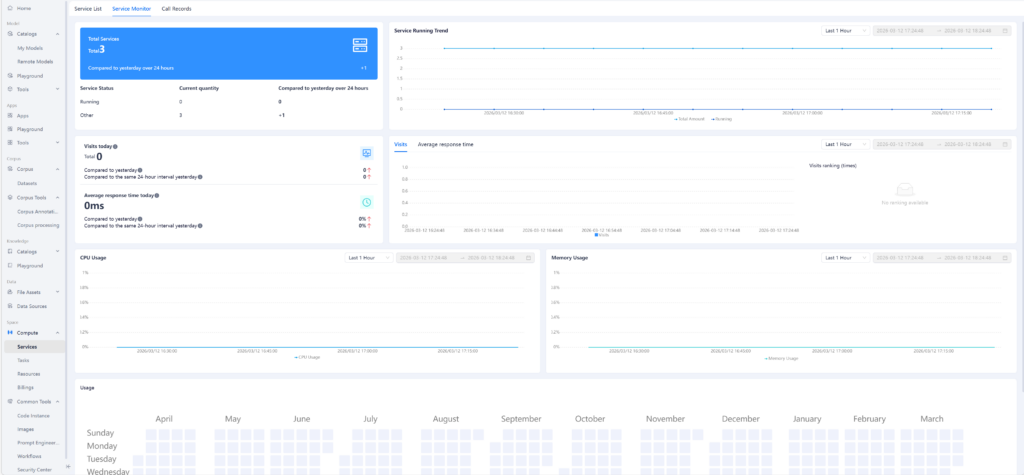
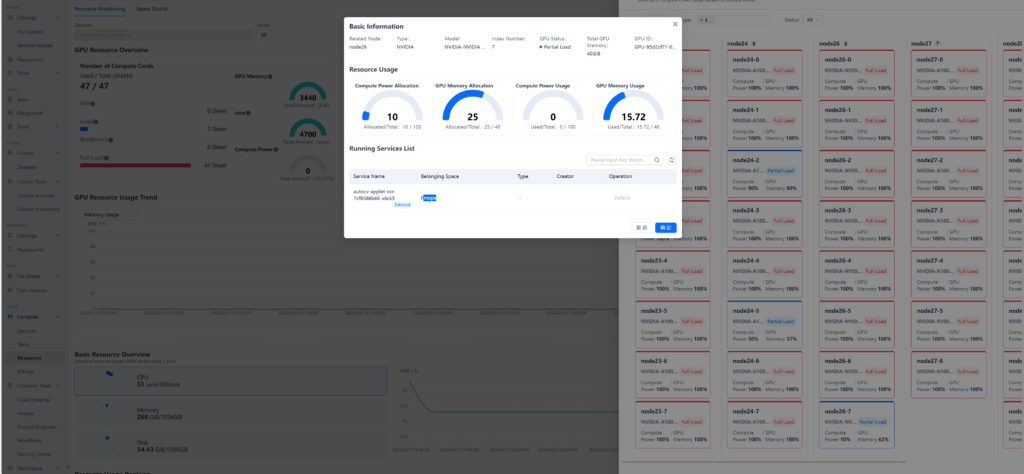

루프 엔지니어링은 사람이 AI에게 프롬프트를 입력하던 역할을 시스템으로 대체하는 것입니다.

AI 코드 분석과 지식 탐색으로 레거시 시스템 현대화 비용을 줄이는 방법과 실제 기업 사례를 소개합니다.

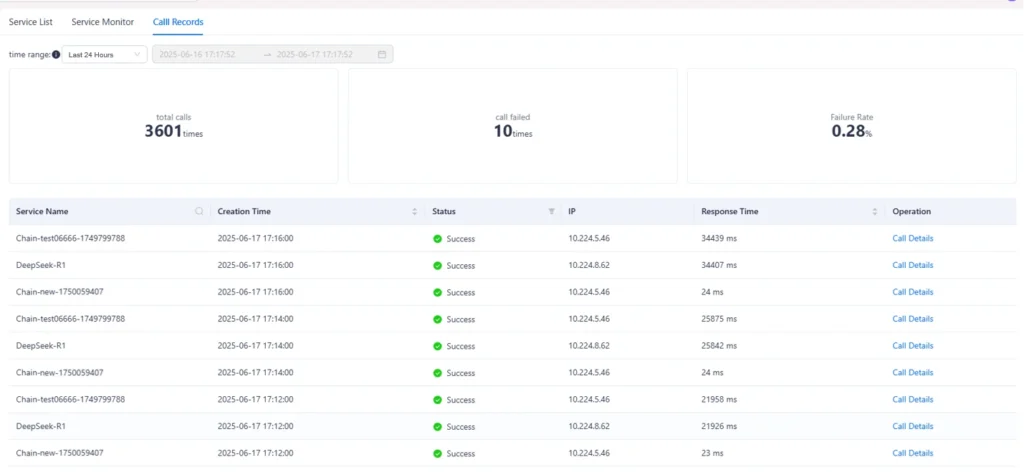
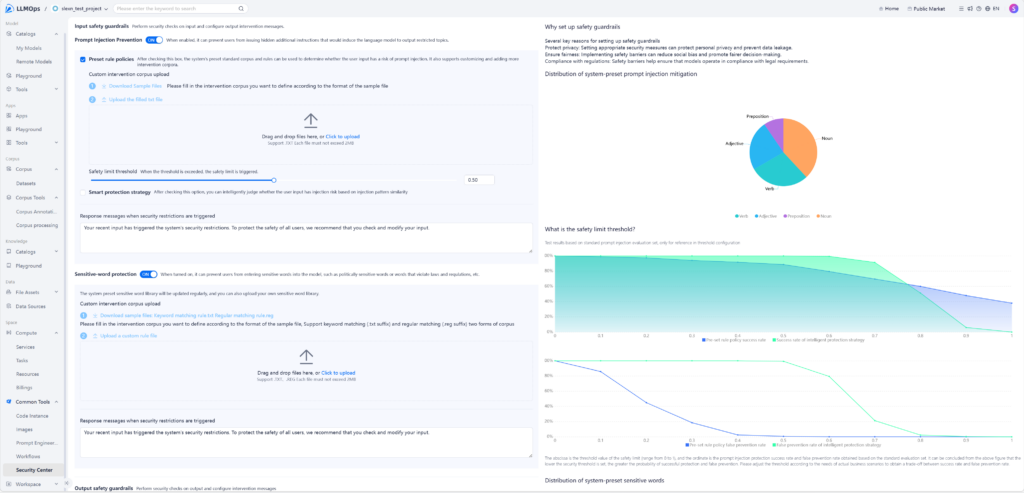
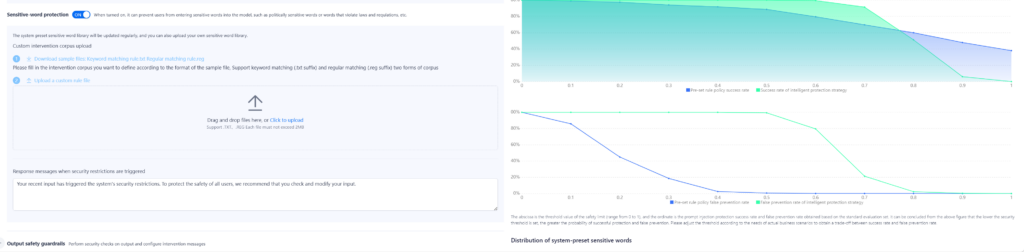
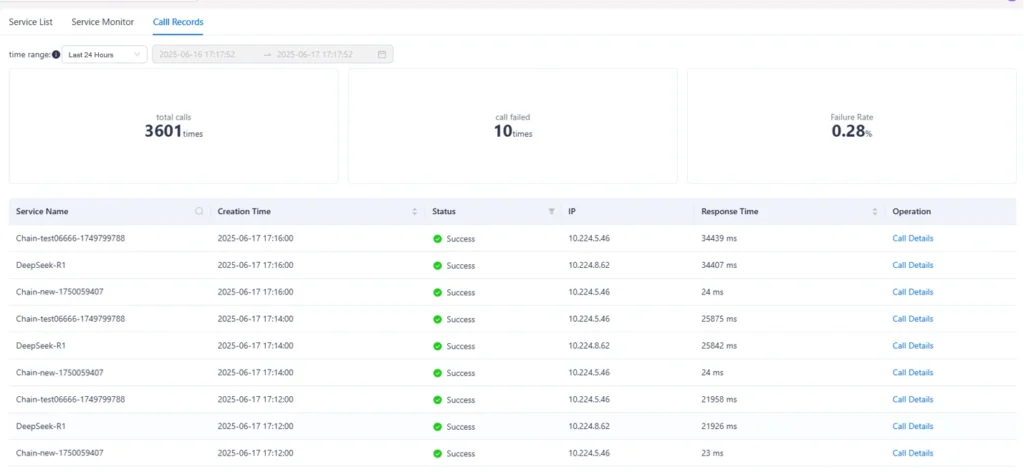
모델 성능뿐 아니라 보안, 권한 관리, 사용 이력, 검증 절차, Human-in-the-loop 승인 체계가 함께 준비되어야 합니다.

글로벌 IT 기업 리서치를 기반으로 대기업 AI 도입이 느린 이유와 엔터프라이즈 AI 운영 방안을 알아봅니다.

완전 폐쇄망 환경에서 조직 단위의 권한 제어와 지식 자산화를 구현하는 CodeCenter 핵심 기능을 알아봅니다.

AI 코드가 망가지는 치명적인 실패 패턴을 진단하고, 100점짜리 프로덕션 코드품질을 완성하는 해결법을 제시합니다.

CodeCenter를 활용해 Java 프로젝트의 성능 병목을 분석하고 개선한 실제 사례를 소개합니다.

2026년 하반기 IT · AI 주요 행사를 정리하고, 기업 관점에서 주목해야 할 기술 흐름과 시사점을 함께 분석합니다.
AI Model Serving 활용 과정에서의 주요 용어들을 기초 개념부터 모델 선택에 필요한 표현까지 순서대로 정리합니다.

시스템 엔지니어링의 비효율을 해결하는 AI 에이전트 Space Agent의 혁신적인 접근을 확인해보세요.

보안 중심 기업 환경에서 Rocket.Chat v8.3 협업툴이 Federation과 화면 공유로 안전한 협업 환경을 지원하는 방식을 소개합니다.

개인의 생산성을 넘어 조직의 보안과 일관성을 지키는 2026년형 엔터프라이즈 AI 코딩 플랫폼을 비교 분석합니다.

Rocket.Chat의 1.2M 메시지 테스트를 통해 대규모 환경에서의 AI 의미 기반 검색 성능과 운영 안정성을 분석합니다.

MCP 기반 DreamFactory로 AI와 기업 데이터를 안전하게 연결하고, 통제된 API 구조로 빠른 AI 도입을 구현합니다.

GPU 수가 아닌 데이터 흐름과 구조 최적화로 AI 인프라 성능과 비용 효율을 동시에 개선하는 방법을 소개합니다.

Git 워크플로우 안에서 AI를 활용해 자연어 검색, PR 자동화, AI 유저로 개발 생산성을 높이는 방법을 소개합니다.

SmartBear의 BearQ는 AI 기반 개발 속도에 대응할 수 있는 새로운 QA 운영 방식을 제시합니다.

AI 기반 개발 프로세스의 변화와 AI-DLC의 개념, 엔터프라이즈 환경에서의 적용 전략을 살펴봅니다.

AI 에이전트 경쟁이 본격화되는 가운데 Self-Hosted 아키텍처의 중요성과 CodeCenter의 위치를 살펴봅니다.

개발 과정의 reasoning을 어떻게 팀의 협업 자산으로 만드는지 살펴봅니다.

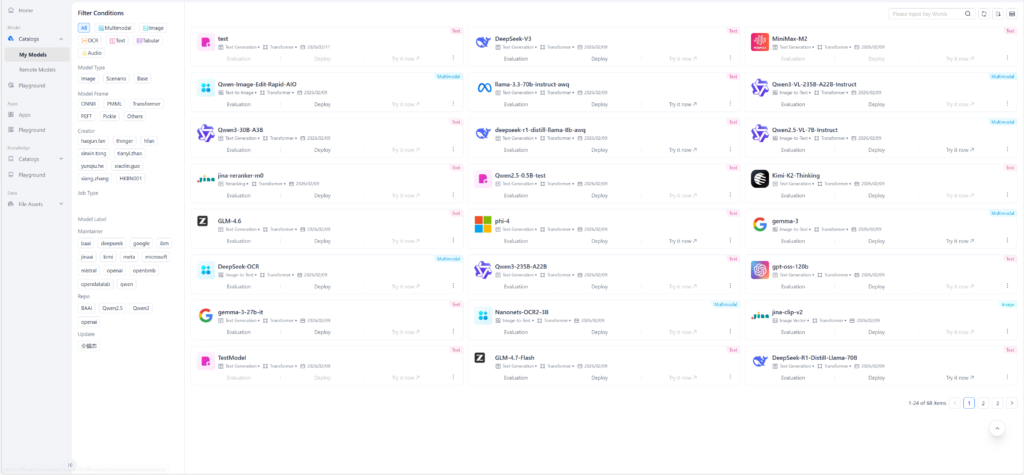
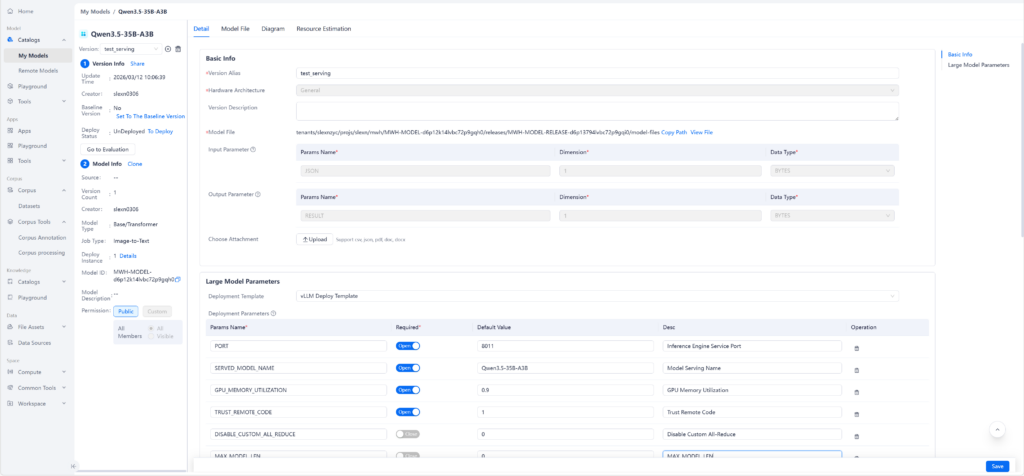
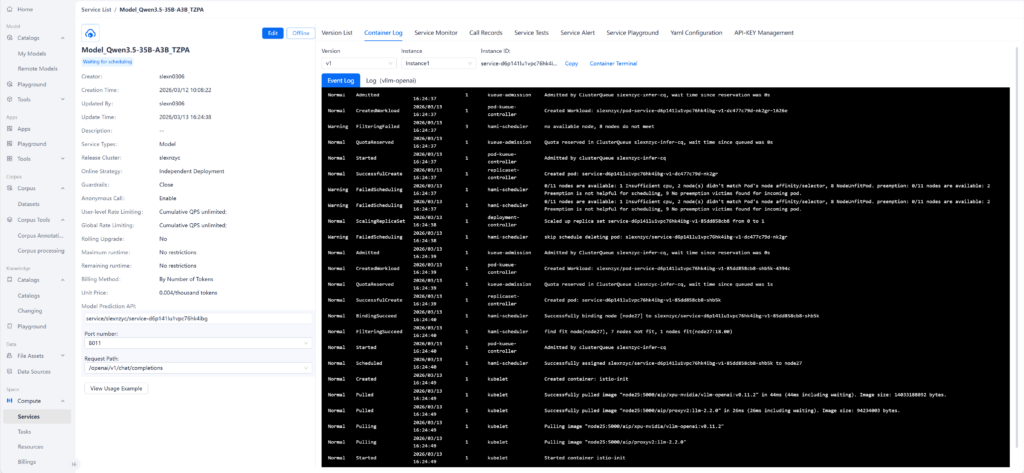
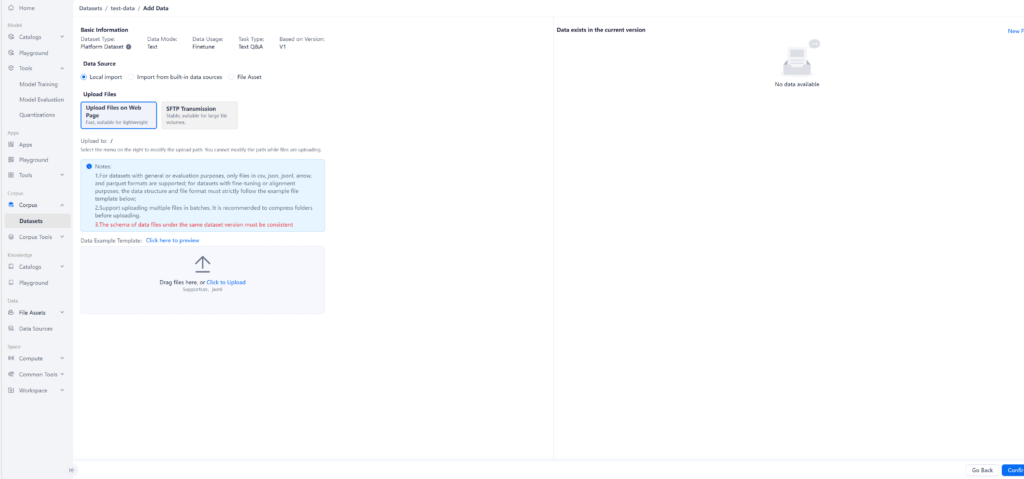
ModelHub는 온프레미스 환경에서 AI 모델의 생애주기를 통합 관리하여, 인프라의 잠재력을 극대화하는 최적의 운영 환경을 제공합니다.

저장소 구조와 문맥 위에서 질문과 탐색을 이어갈 수 있는 CodeCenter의 Workspace를 소개합니다.

Agentic SDLC의 핵심은 보안과 운영 환경 속에서 지속 가능하게 활용할 수 있는 자동화 전략을 구축하는 것입니다.

AI Agent 도입을 검토 중이라면, 보안·비용·운영 관점에서 미리 점검해야 할 6가지 판단 기준을 확인해보세요.

AI가 결과물을 대신 만드는 시대, 판단 기준과 배제의 논리가 어떻게 경쟁력을 만드는지 살펴봅니다.

AI가 코드를 만드는 시대, 주니어 개발자는 어떻게 살아남을까? AI 코딩 도구 이후 달라진 개발자 역할과 평가 기준을 알아봅니다.

CES 2026을 통해 하드웨어와 결합된 물리적 AI와 에이전틱 AI가 일상과 산업의 구조를 어떻게 바꾸고 있는지 살펴봅니다.

최근 소프트웨어 트렌드를 통해 기술 유행과 현실 사이의 간극을 짚어봅니다.

AI 자동화 영역과 인간 개입 지점을 명확히 구분하는 것은 Agentic AI를 운영 가능한 시스템으로 만드는 핵심 판단 기준입니다.

QA 자동화의 개념과 도입 시점, 핵심 이점부터 Agentic AI 기반 테스트 자동화의 최신 흐름까지 한눈에 정리합니다.





